Thema · 4 Beiträge
Verteilte Systeme
Konsens, Replikation, Partitionierung - und was um 3 Uhr morgens versagt.
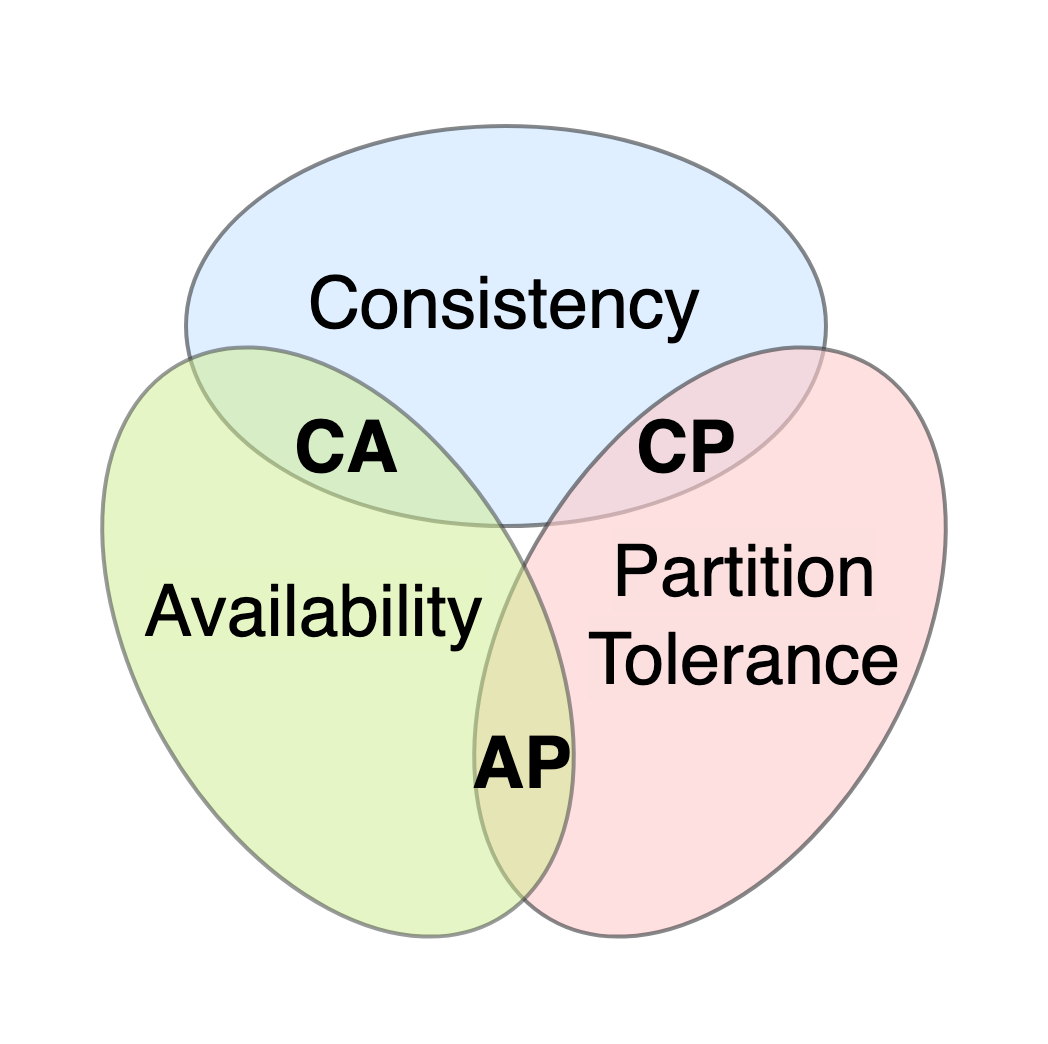
Distributed systems are mostly theory until the first partition; after that, they’re mostly operations. The theorems still matter - they tell you which failure modes are unavoidable - but the day-to-day is timeout tuning, replica promotion drills, and arguing about whether “eventual” is good enough for this particular counter.
Posts under this hub land as I write them; right now /stack/go and
/stack/kafka are the closest pointers to operational practice in the
repo.
§ Beiträge
Verteilte Systeme
- März 2026 Einen lokalen LLM-Stack in deine Engineering-Pipeline einbauen Ollama auf eigener GPU, llama.cpp für CPU, vLLM für Throughput - in die Engineering-Pipeline verdrahtet neben Postgres und Redis. Kein Experiment, echte Arbeit.
- Juli 2025 Event-Driven-Architekturen, die tatsächlich geshipt wurden Die meisten Event-Driven-Rewrites sterben mit 80 % des Buses gebaut und null der harten Probleme gelöst. Was den einen unterscheidet, der bei Bytro geshipt hat.
- März 2025 Fulcrum: die Agent Control Plane, die ich selbst gebaut habe Warum ich eine eigene Agent Control Plane schrieb. TLDR: keine der existierenden machte die operativen Teile, die Multi-Agent erst benutzbar machen.
- Apr. 2024 Telecom-Billing, GWT und warum Salesforce dich hasst Cloud-Billing für Telecom und Salesforce-Integration: was passiert, wenn zwei Datenmodelle grundsätzlich widersprechen und warum das so weh tut.