主题 · 4 篇
分布式系统
共识、复制、分区,以及凌晨3点故障的那些部分。
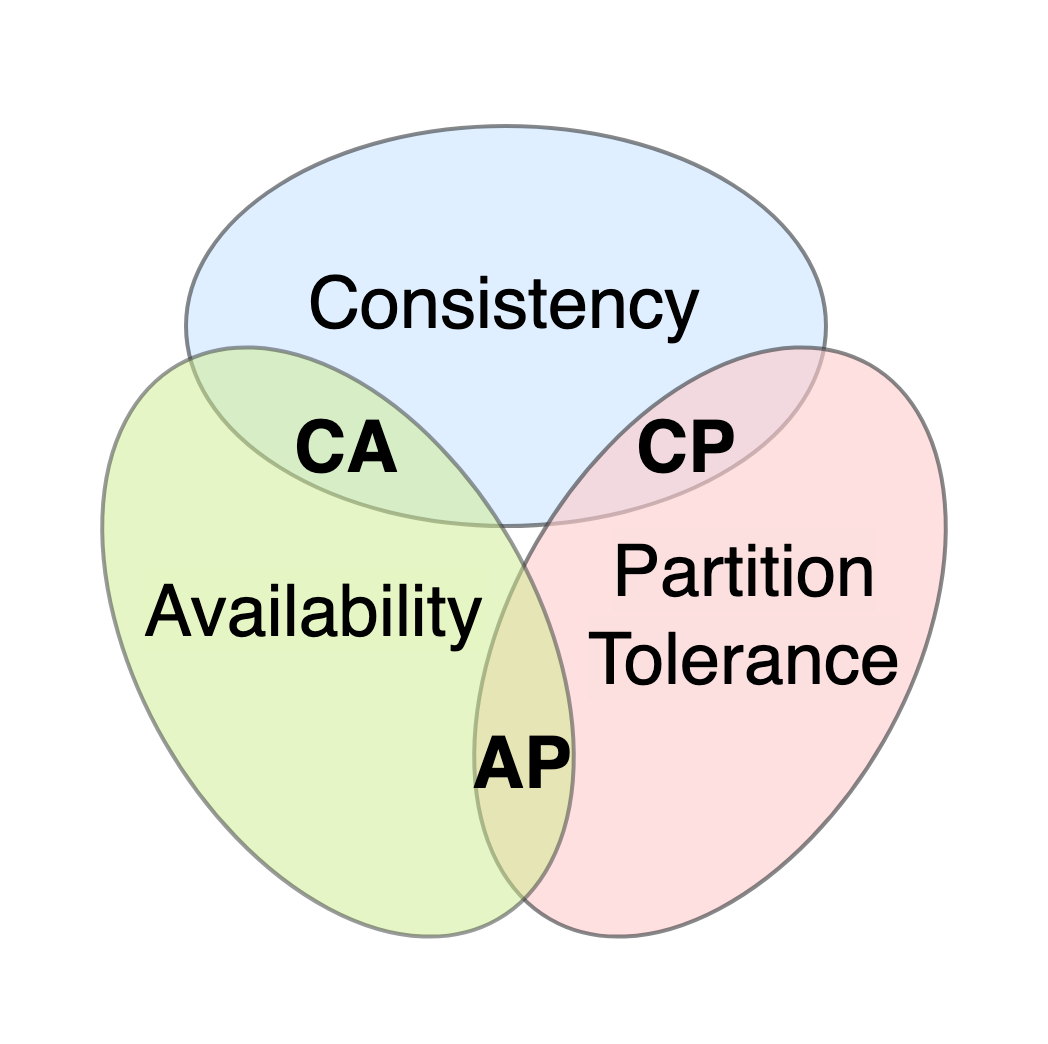
Distributed systems are mostly theory until the first partition; after that, they’re mostly operations. The theorems still matter - they tell you which failure modes are unavoidable - but the day-to-day is timeout tuning, replica promotion drills, and arguing about whether “eventual” is good enough for this particular counter.
Posts under this hub land as I write them; right now /stack/go and
/stack/kafka are the closest pointers to operational practice in the
repo.
§ 文章
分布式系统
- 2026年3月 把本地 LLM 栈接进你真正的工程流水线 Ollama 跑在你自己的 GPU 上,llama.cpp 做 CPU 工作,vLLM 处理吞吐量--全部接入和你测试命令同一条工程流水线。这不是科学实验,这是我过去一年里真正在用的设置。
- 2025年7月 真正上线的事件驱动架构长什么样 大多数事件驱动重写死于消息总线建好了80%、困难问题一个没解决的时候。这是我在 Bytro 历时两年、真正交付的那次,与两次死掉的工程之间的差别--那个差别跟架构图说的无关。
- 2025年3月 Fulcrum:我因为别的方案不合用而自己造的 agent 控制面 市面上已有几十个 agent 框架,为什么还要再写一个?老实说:没有一个把那些让多 agent 工作在每年3400次提交规模上真正可用的枯燥运维部分做好--所以我自己造了一个。
- 2024年4月 电信计费、GWT 与 Salesforce 为什么恨你 为电信运营商搭建云计费平台、用 Talend ETL 打通 Salesforce 时学到的教训:当两套数据模型从根本上不一致时,集成的第一阶段是分类学而非代码,GWT 类型安全和 BPMN 工作流如何在 2013 年的企业 Java 里各司其职。