Topic · 4 posts
Distributed systems
What CAP, FLP, and the rest of the theory look like after contact with a real cluster. Leader election, replication lag, partitions, and the operational cost of each knob.
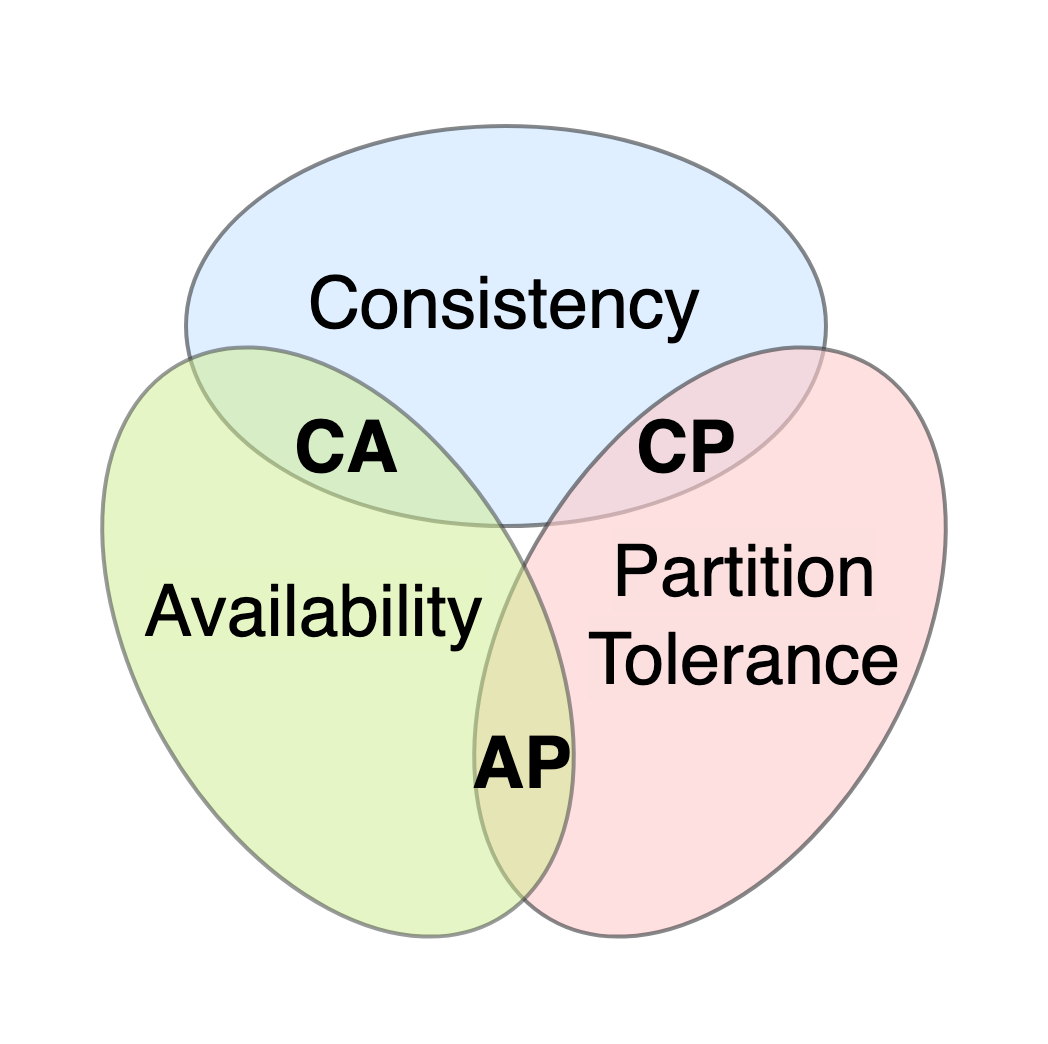
Distributed systems are mostly theory until the first partition; after that, they’re mostly operations. The theorems still matter - they tell you which failure modes are unavoidable - but the day-to-day is timeout tuning, replica promotion drills, and arguing about whether “eventual” is good enough for this particular counter.
Posts under this hub land as I write them; right now /stack/go and
/stack/kafka are the closest pointers to operational practice in the
repo.
§ Writing
All writing on distributed systems
- Mar 2026 Running a local LLM stack inside your actual engineering pipeline Ollama on a GPU you own, llama.cpp for CPU work, vLLM for throughput - wired into the same engineering pipeline that runs your tests. Not a science project.
- Jul 2025 Event-driven architectures that actually shipped Most event-driven rewrites die with 80% of the bus built and zero hard problems solved. Here's what separated the one that shipped at Bytro from the graveyard.
- Mar 2025 Fulcrum: the agent control plane I built because others didn't fit Why I wrote a local-first agent control plane when dozens exist. TLDR: none handled the boring operational parts that make multi-agent work usable.
- Apr 2024 Telecom billing, GWT, and why Salesforce hates you What I learned building a cloud billing platform for telecom operators and integrating it with Salesforce when the data models fundamentally disagreed.
§ Related